Multi-Loco: Unifying Multi-Embodiment Legged Locomotion via Reinforcement Learning Augmented Diffusion




Generalizing locomotion policies across diverse legged robots with varying morphologies is a key challenge due to differences in observation/action dimensions and system dynamics. In this work, we propose Multi-Loco, a novel unified framework combining a morphology-agnostic generative diffusion model with a lightweight residual policy optimized via reinforcement learning (RL). The diffusion model captures morphology-invariant locomotion patterns from diverse cross-embodiment datasets, improving generalization and robustness. The residual policy is shared across all embodiments and refines the actions generated by the diffusion model, enhancing task-aware performance and robustness for real-world deployment. We evaluated our method with a rich library of four legged robots in both simulation and real-world experiments. Compared to a standard RL framework with PPO, our approach - replacing the Gaussian policy with a diffusion model and residual term - achieves a 10.35% average return improvement, with gains up to 13.57% in wheeled-biped locomotion tasks. These results highlight the benefits of cross-embodiment data and composite generative architectures in learning robust, generalized locomotion skills.

Deployment of the reinforcement learning augmented diffusion policy on four platforms (biped, wheeled biped, humanoid and quadruped). The experimental results demonstrate that the unified policy can effectively control the robots across various types of uneven terrain, including grass, slopes, stairs, and gravel paths. These results highlight the policy's robustness and exceptional control capabilities.
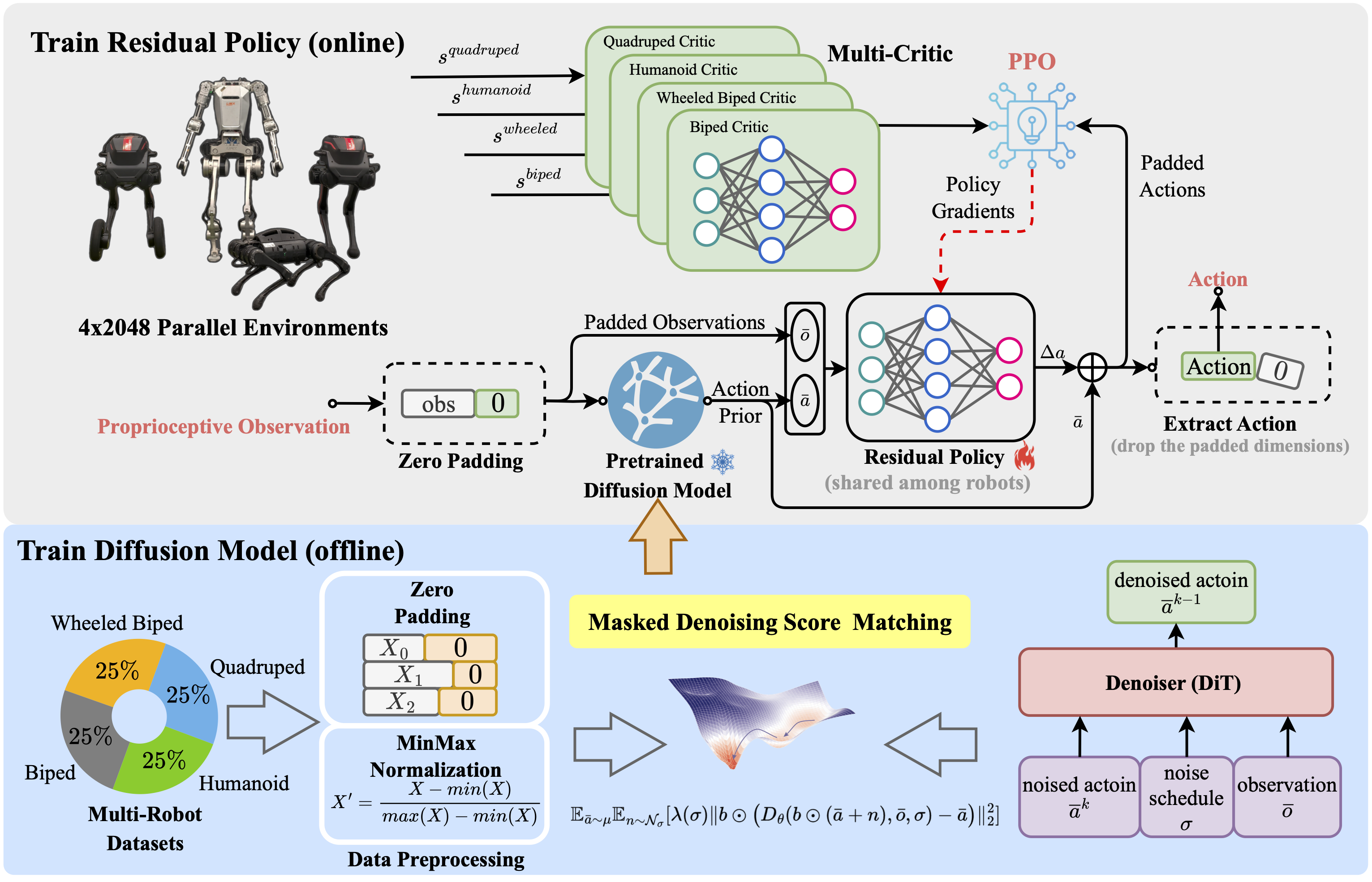
Overview of the Multi-Loco framework. Multi-robot datasets are preprocessed via zero-padding and normalization to align observation and action spaces across embodiments. A shared diffusion model is trained offline using masked denoising score matching. At inference time, the diffusion model generates action priors, which are refined by a residual policy trained via multi-critic PPO. Each critic specializes in one robot type, while the policy remains shared across all embodiments.
@article{yang2025multiloco,
title={Multi-Loco: Unifying Multi-Embodiment Legged Locomotion via Reinforcement Learning Augmented Diffusion},
author={Shunpeng Yang and Zhen Fu and Zhefeng Cao and Guo Junde and Patrick Wensing and Wei Zhang and Hua Chen},
year={2025},
eprint={2506.11470},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2506.11470},
}